StudioOne
스튜디오원(Studio One): 믹스 더킹으로 보컬 우선 순위를 지정하는 방법
페이지 정보
본문
https://blog.presonus.com/2023/12/29/how-to-prioritize-vocals-with-mix-ducking/
믹스 더킹으로 보컬 우선 순위를 지정하는 방법
이는 음성 해설 및 팟캐스트를 위한 더 나은 더킹 팁 과 더 이상 압축을 사용하지 않는 이유 팁을 보완합니다 . 전체 믹스에 보이스오버 더킹 개념을 적용합니다. 요약은 다음과 같습니다. 마스터 버스에 Pro EQ 3를 삽입하고 , 보컬 트랙에서 사이드체인을 공급하고, Pro EQ 3 의 다이내믹 EQ를 조정하여 스테레오 믹스의 보컬 주파수를 줄입니다. 미묘하게 수행하면 뒤에 있는 믹스가 덜 눈에 띄기 때문에 목소리가 더욱 눈에 띄게 됩니다.
보조 메인 버스 생성
Pro EQ 3 를 메인 버스에 삽입하면 보컬이 메인 버스로 이동하기 때문에 작동하지 않습니다. 따라서 동적 EQ는 우리가 원하지 않는 믹스뿐만 아니라 음성에도 영향을 미칩니다. 해결책은 보조 메인 버스를 생성하는 것입니다. 우리는 그것을 서브 버스라고 부를 것입니다.
1. 믹스에서 모든 트랙을 선택합니다 (가장 낮은 번호의 트랙을 클릭하고 가장 높은 번호의 트랙을 Shift+클릭).
2. 보컬 트랙을 Ctrl/Cmd 클릭하여 선택을 취소합니다. 다른 트랙은 계속 선택되어 있어야 합니다.
3. 선택한 트랙 중 하나를 마우스 오른쪽 버튼으로 클릭하고 "선택한 채널에 버스 추가"를 선택합니다(그림 1).
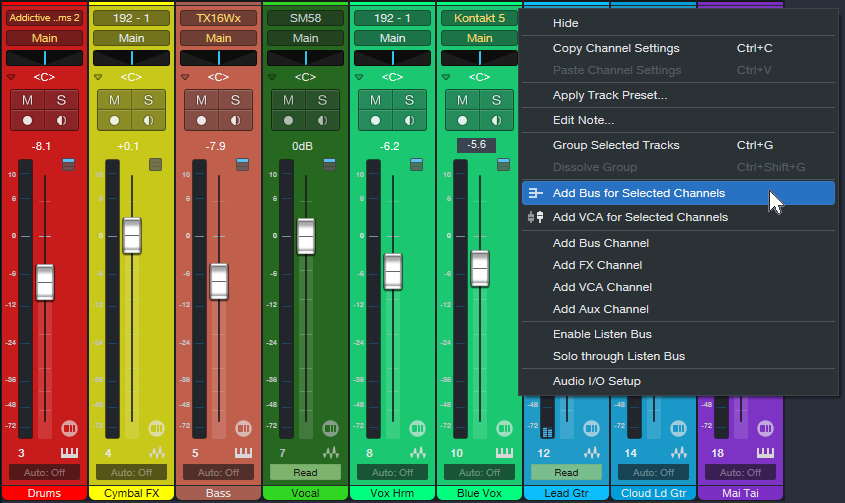
그림 1: 보컬 트랙(7)을 제외한 모든 트랙이 선택되었습니다. 이들은 메인 버스에서 새로운 서브 버스로 다시 할당될 예정입니다.
4. 새로운 서브 버스가 메인 버스에 전원을 공급합니다. 여전히 메인 버스로 가는 보컬 트랙을 제외하고 모든 트랙 출력이 서브 버스로 가는지 확인하십시오. 이제 보컬과 독립적으로 서브 버스를 처리할 수 있습니다.
5. Pro EQ 3 를 서브 버스에 삽입합니다. 보컬 트랙의 센드를 Pro EQ 3 의 사이드체인에 삽입하세요. 그림 2는 단순화된 신호 흐름도입니다.
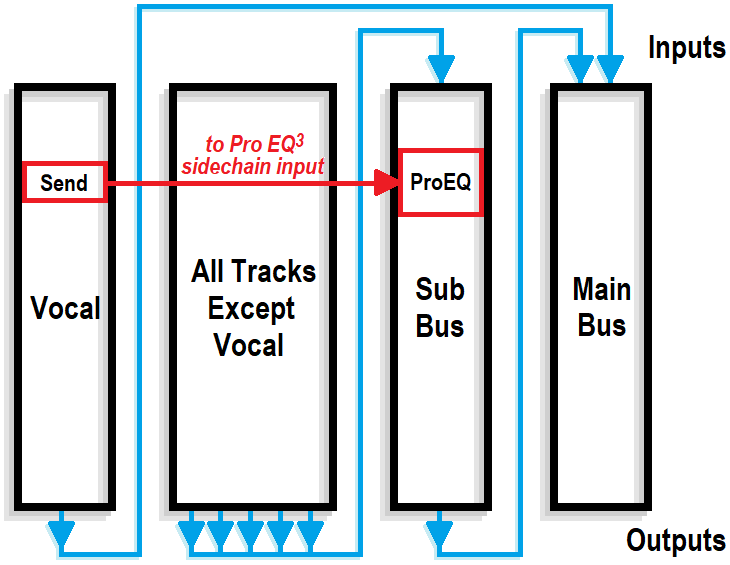
그림 2: 보컬을 제외한 모든 트랙은 서브 버스로 이동합니다. 서브 버스 출력과 보컬 출력은 메인 버스로 이동합니다. 보컬 트랙의 전송은 서브 버스에 삽입된 Pro EQ 3 의 사이드체인을 구동합니다.
6. 이제 가장 중요한 부분인 최적의 다이나믹 EQ 설정을 선택해야 합니다. 목표는 음성에 해당하는 주파수 범위에 동적 컷을 추가하는 것입니다. 그림의 설정. 3은 이 프로세스를 실험하기 위한 좋은 시작입니다.
- 주파수는 한 옥타브 간격으로 설정됩니다.
- 범위는 최대 음수 값입니다.
- Q 설정은 2.0입니다.
- 사이드체인은 보컬에서 나오는 신호에 대해 활성화됩니다.
7. 보컬 피크가 미묘한 컷을 유발하도록 각 단계의 임계값을 조정합니다. 그림 3은 12dB의 범위를 보여 주므로 표시된 컷은 약 -2dB ~ -3dB입니다. 별로 없어 보일 수도 있지만 보컬을 위한 공간을 여는 데는 충분합니다.
8. 각 임계값 매개변수의 설정을 최적화합니다. 처리된 사운드와 처리되지 않은 사운드를 비교하려면 보컬 트랙의 보내기를 끄십시오. 대신 Pro EQ 3 에서 사이드체인을 비활성화하지 마십시오 . 그렇지 않으면 EQ가 보컬 대신 믹스의 다이내믹에 반응하게 됩니다.
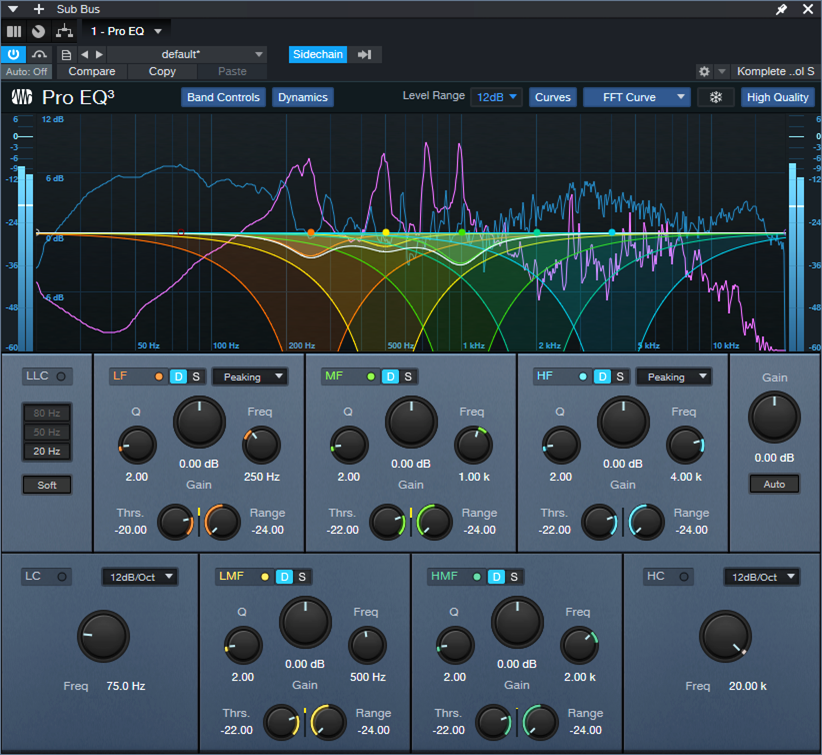
그림 3: 보라색 파형은 사이드체인에 공급되는 보컬입니다. 파란색 파형은 스테레오 믹스입니다. 색칠된 곡선은 5개의 EQ 단계입니다. LF 및 HF를 피킹 모드로 설정합니다. 중앙을 향한 흰색 물결선은 이 스크린샷을 찍을 때 발생한 컷의 양을 보여줍니다.
9. 보컬 트랙의 보내기 슬라이더를 사용하여 Pro EQ 3 의 사이드체인으로 가는 레벨을 미세 조정합니다.
이 기술은 압축이나 더 이상 압축을 사용하지 않는 이유에 대한 블로그 게시물의 기술에서 보컬이 일관된 다이내믹 레인지를 가지고 있다고 가정합니다. 그렇지 않으면 시끄러운 부분이 배경을 더 아래로 밀어내지만 보컬이 가장 클 때는 더 낮은 레벨이 필요하지 않습니다. 보컬의 다이내믹이 문제인 경우 보컬 트랙의 보내기를 자동화하여 시끄러운 보컬 섹션의 자르기 양을 줄입니다.
변수가 너무 많기 때문에 사운드를 최적화하는 방법도 다양합니다.
- Q를 좁히면 서브믹스에 큰 영향을 주지 않고 이 기술의 많은 이점을 얻을 수 있습니다.
- Range 매개변수를 그림과 같이 낮게 설정하고 싶지 않을 수도 있습니다. 3, 임계값 설정이 너무 낮아 절단이 너무 깊어지는 것을 방지하는 "가드레일"이 있습니다.
- Q를 넓히면 효과가 더 넓은 주파수 범위에 적용되므로 많이 줄일 필요가 없습니다(그림 4). 이는 음성 해설에 사용되는 전통적인 더킹과 더 비슷합니다.
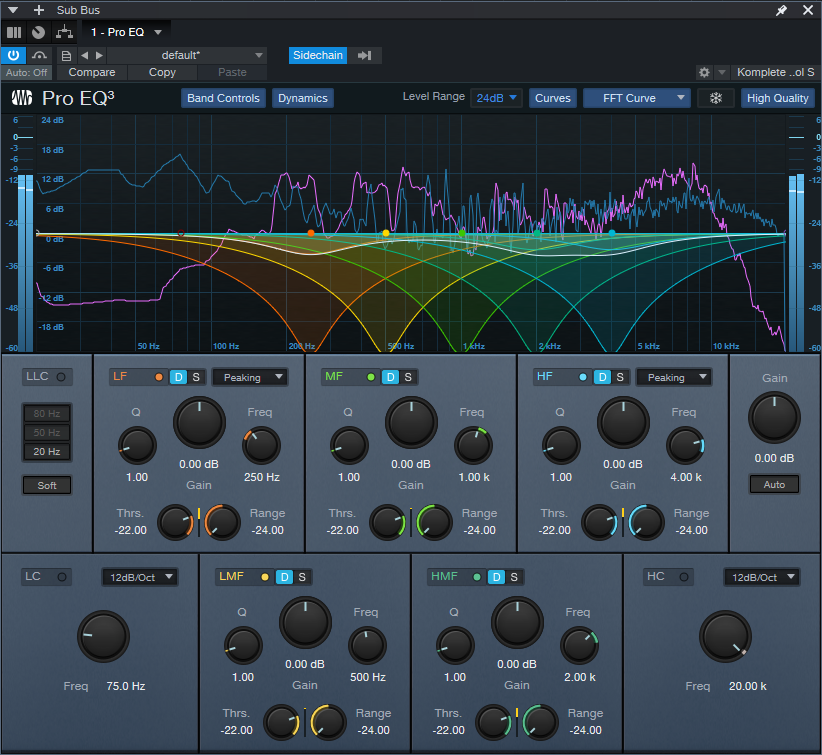
그림 4: Q 설정이 넓을수록 컷 집중도가 떨어집니다.
이 기술의 의도는 미묘한 향상을 추가하는 것이며 작업이 필요한 믹스, 편곡 또는 보컬에 대한 치료법이 아니라는 점을 기억하십시오. 그러나 보컬을 좀 더 돋보이게 하고 믹스에 더 편안하게 어울리는 추가적인 작은 무언가를 제공할 수 있습니다.
등록된 댓글이 없습니다.
첫번째 댓글을 달아보세요!